A series on automatic differentiation in Julia. Part 3 uses metaprogramming based on IRTools.jl to generate a modified (primal) forward pass and to reverse differentiate it into a backward pass. This is a more robust approach than the expression based approach in Part 2.
This is part of a series. The other articles are:
All source code can be found at MicroGrad.jl. The code here is based on the example at IRTools.jl.
Table of Contents
1 Introduction
Part 1 introduced the rrule for implementing chain rules
and Part 2 defined a @generated pullback function for inspecting and decomposing complex code.
The goal here is to replicate the results of Part 2 except in a more robust manner using the IRTools.jl package.
For example, from part 1 there are rrules for +, * and /.
The goal is then to automatically differentiate the following:
like so:
f(a, b) = a / (a + b*b)
z, back = pullback(f, 2.0, 3.0) # (0.1818, ∂(f))
back(1.0) # (nothing, 0.0744, -0.099)where pullback is a @generated function that inspects the Intermediate Representation (IR) code for f:
using IRTools
ir = @code_ir f(2, 3)
#= 1: (%1, %2, %3)
%4 = %3 * %3
%5 = %2 + %4
%6 = %2 / %5
return %6
=#This is an advanced use of the Julia programming language. You should be comfortable with the language before reading this post. At the very least, the Julia documentation page on metaprogramming is required for this post and will be considered assumed knowledge, especially the sections on “Expressions and evaluation”, “Code Generation” and “Generated Functions”. I also suggest going through the IRTools.jl documentation first.
This post can be read independently to Part 2 and will repeat parts of it. However it is advised to read Part 2 first because it is easier to understand than this post.
2 Differentiating Wengert Lists
The Zygote.jl automatic differentiation (AD) package is a realisation of the paper Don’t Unroll Adjoint: Differentiating SSA-Form Programs (2019) by Michael J Innes.
The paper works with Wengert lists, also known as tapes, and a generalisation of it called Static Single Assignment (SSA) form.
The aim here is to develop a minimal AD package, so this series only focuses on the sections on Wengert lists.
A consequence is that the code will not be to handle any non-linear logic in Julia, for example any control flow like if, while or for blocks.
The paper uses the same example as the introduction:
\[f(a, b) = \frac{a}{a + b^2} \tag{2.1} \label{eq:f}\]This can be broken down into smaller steps where each intermediate variable is saved. This is known as a Wengert list, or tape, or (backpropagation) graph:
\[\begin{align} y_1 &= b \times b \\ y_2 &= a + y_1 \\ y_3 &= a / y_2 \end{align} \tag{2.2} \label{eq:f_wengert}\]To differentiate this, all function calls are wrapped with a differentiation function $\mathcal{J}$ which returns both the output $y$ and a pullback function $\mathcal{B}$. This is called the primal form:
\[\begin{align} y_1, \mathcal{B}_1 &\leftarrow \mathcal{J}(\times, b, b) \\ y_2, \mathcal{B}_2 &\leftarrow \mathcal{J}(+, a, y_1) \\ y_3, \mathcal{B}_3 &\leftarrow \mathcal{J}(/, a, y_2) \end{align} \tag{2.3} \label{eq:primal}\]The pullback function $\mathcal{B}$ takes as input the gradient of a scalar $l$ (typically a loss function) to a function $y(x)$ and returns the gradient with regards to the variable $x$. This partial gradient $\frac{\partial l}{\partial x}$ is written as $\bar{x}$.
\[\begin{align} \bar{x} &= \frac{\partial l}{\partial x} = \frac{\partial l}{\partial y} \frac{\partial y}{\partial x} \end{align} \tag{2.4} \label{eq:bar_x}\]so we can write in this mathematical notation as:
\[\begin{align} \bar{x} &\leftarrow \mathcal{B}(\bar{y}) = \bar{y} \frac{\partial y}{\partial x}\\ \text{or} \quad \bar{x} &\leftarrow \mathcal{B}(\bar{y}) = J^{\dagger}\bar{y} \end{align} \tag{2.5} \label{eq:pullback}\]where $\bar{y}=\frac{\partial l}{\partial y}$ and $J=\frac{\partial y}{\partial x}$ is the Jacobian (gradient) for arrays.
The various partial gradients are calculated by reversing the list. Each pullback function $\mathcal{B}_i$ takes as input the previous gradient $\bar{y}_i$. The input is an existing gradient $\Delta$. At the start this is usually set to 1:
\[\begin{align} \text{s̄elf}_3, \bar{a}_{3,1}, \bar{y}_2 &\leftarrow \mathcal{B}_3(\Delta) \\ \text{s̄elf}_2, \bar{a}_{2,1}, \bar{y}_1 &\leftarrow \mathcal{B}_2(\bar{y}_2) \\ \text{s̄elf}_1, \bar{b}_{1,1}, \bar{b}_{1,2} &\leftarrow \mathcal{B}_1(\bar{y}_1) \end{align} \tag{2.6} \label{eq:reverse}\]The final step is to accumulate the gradients for variables which are used multiple times:
\[\begin{align} \bar{a} &\leftarrow \bar{a}_{3,1} + \bar{a}_{2,1} \\ \bar{b} &\leftarrow \bar{b}_{1,1} + \bar{b}_{1,2} \\ \end{align} \tag{2.7} \label{eq:accumulate}\]This end result is equivalent to rolling everything up into one function using the multivariable chain rule:
\[\begin{align} \bar{a} &= \frac{\partial l}{\partial a} = \mathcal{B}_{3,a}(\Delta) + \mathcal{B}_{2,a}(\bar{y}_2) \\ &= \frac{\partial l}{\partial y_3} \frac{\partial y_3}{\partial a} + \frac{\partial l}{\partial y_2} \frac{\partial y_2}{\partial a} \\ &= \Delta \cdot \frac{\partial }{\partial a} \left( \frac{a}{y_2}\right) + \left(\frac{\partial l}{\partial y_3}\frac{\partial y_3}{\partial y_2} \right)\frac{\partial}{\partial a}(a + y_1) \\ &= \Delta \frac{1}{y_2} + \left(\Delta \frac{-a}{y_2^2} \right) (1+0) \\ &= \Delta \frac{b^2}{(a+b^2)^2} \\ \bar{b} &= \frac{\partial l}{\partial b} = 2 \mathcal{B}_{1,b}(\bar{y}_1) \\ &= 2\frac{\partial l}{\partial y_1} \frac{\partial y_1}{\partial b} \\ &= 2 \left(\frac{\partial l}{\partial y_3}\frac{\partial y_3}{\partial y_2}\frac{\partial y_2}{\partial y_1} \right) \frac{\partial y_1}{\partial b} \\ &= 2 \left(\Delta \cdot \frac{\partial}{\partial y_2}\left(\frac{a}{y_2}\right) \cdot \frac{\partial}{\partial y_1}(a + y_1) \right)\frac{\partial}{\partial b'}(b'\times b) \\ &= 2\left(\Delta \left(-\frac{a}{y_2^2}\right)(0+1)\right)b \\ &= -\frac{2ab\Delta}{(a+b^2)^2} \end{align} \tag{2.8} \label{eq:rollup}\]3 Pullback
3.1 Definition
The goal is to generate code which automatically implements the equations of section 2.
To start, define a pullback function (source):
function pullback endThis will be turned into a generated function.
Julia changed the behaviour of generated functions in version 1.10.
Before 1.10, they always had access to the world age counter.
This is a single number that is incremented every time a method is defined, and helps optimise compilations.
However from version 1.10 generated functions Base.get_world_counter() will only return typemax(UInt).
This is to prevent reflection - code inspection - in generated functions.1
However the code here relies on reflection.
Thankfully, there is a hack that Zygote.jl uses to access the world age in pullback.
Because of this, the definition of pullback is different based on the version, but both will forward to a common internal _generate_pullback function.
@generated function pullback(f, args...)
_generate_pullback(nothing, f, args...)
endfunction _pullback_generator(world::UInt, source, self, f, args)
ret = _generate_pullback(world, f, args...)
ret isa Core.CodeInfo && return ret
stub = Core.GeneratedFunctionStub(identity, Core.svec(:methodinstance, :f, :args), Core.svec())
stub(world, source, ret)
end
@eval function pullback(f, args...)
$(Expr(:meta, :generated, _pullback_generator))
$(Expr(:meta, :generated_only))
end3.2 ChainRules
The first goal of _generate_pullback will be to forward the function and its arguments to a matching rrule if it exists.
For now it will throw an error if it cannot find one.
function _generate_pullback(world, f, args...)
T = Tuple{f, args...}
if (has_chain_rrule(T, world))
return :(rrule(f, args...))
end
:(error("No rrule found for ", repr($T)))
endIn part 1 the most generic method of rrule was defined for an Any first argument, so if the compiler dispatches to this method it means no specific rrule was found.2
using IRTools: meta
function has_chain_rrule(T, world)
Tr = Tuple{typeof(rrule), T.parameters...}
meta_T = meta(Tr; world=world)
if isnothing(meta_T)
return false
end
method_ = meta_T.method
sig = method_.sig
!(sig isa DataType) || (sig.parameters[2] !== Any)
endLet’s test all this code from bottom to top for a function with an rrule and one without: + and f(a,b)=a/(a+b*b).
As a reminder, generated functions only have access to a variables types, so to test the _generate_pullback and all functions under it, we can only work with the types.
Firstly, for + acting on floats (redefine @generated pullback if necessary):
world = Base.get_world_counter()
T = Tuple{typeof(+), Float64, Float64}
has_chain_rrule(T, world) # true
_generate_pullback(world, typeof(+), Float64, Float64) # :(rrule(f, args...))
pullback(+, 1.0, 2.0) # (3.0, var"#add_back#5"())Now for f, also acting on floats:
world = Base.get_world_counter()
T = Tuple{typeof(f), Float64, Float64}
has_chain_rrule(T, world) # false
_generate_pullback(world, typeof(f), Float64, Float64) # :(error(...))
pullback(f, 1.0, 2.0) # ERROR: No rrule found for ...The more interesting task is to inspect f and apply the equations of section 2 to fully differentiate with respect to all input parameters.
3.3 IR
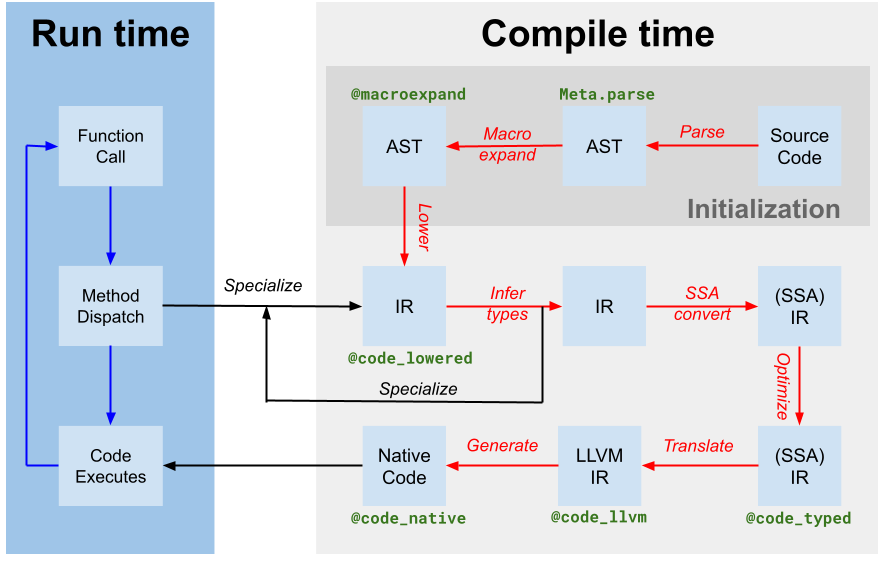
The first step is to create a Wengert list for f in Intermediate Representation (IR) form.
Julia already does this as part of the compilation process.
IRTools.jl mimics this internal IR form with its own custom IR struct.
It can be generated as follows:
using IRTools: IR, meta
T = Tuple{typeof(f), Float64, Float64}
m = meta(T; world=Base.get_world_counter())
ir = IR(m)
#=
1: (%1, %2, %3)
%4 = %3 * %3
%5 = %2 + %4
%6 = %2 / %5
return %6
=#The returned object corresponds exactly to $\ref{eq:f_wengert}$.
Using this knowledge, we can now create a new function _generate_pullback_via_decomposition which will be called if no rrule exists.
It uses the IR to create the primal (equation $\ref{eq:primal}$) (source).
using IRTools: meta, IR, blocks
function _generate_pullback_via_decomposition(T, world)
m = meta(T; world=world)
isnothing(m) && return nothing
ir = IR(m)
length(blocks(ir)) == 1 || error("control flow is not supported")
pr, calls = primal(ir, T)
m, pr, calls
end3.4 Primal
The goal here is to create an IR for equation $\ref{eq:primal}$. This is what it will look like:
1: (%1, %2, %3)
%4 = Main.pullback(Main.:*, %3, %3)
%5 = Base.getindex(%4, 1)
%6 = Base.getindex(%4, 2)
%7 = Main.pullback(Main.:+, %2, %5)
%8 = Base.getindex(%7, 1)
%9 = Base.getindex(%7, 2)
%10 = Main.pullback(Main.:/, %2, %8)
%11 = Base.getindex(%10, 1)
%12 = Base.getindex(%10, 2)
%13 = Base.tuple(%6, %9, %12)
%14 = (Pullback{Tuple{typeof(f), Float64, Float64}})(%13)
%15 = Base.tuple(%11, %14)
return %15Although harder to read, this code represents the same code as the expressions in part 2.
The primal function first wraps the existing IR with Pipe to make inserts more efficient.
It defines two arrays to store information (source):
using IRTools: block, isexpr, finish, Pipe, Variable, return!, returnvalue, stmt, xcall
function primal(ir::IR, T=Any)
pr = IRTools.Pipe(ir)
calls = []
pullbacks = []The calls array stores the subset of variables that require a pullback.
Because the IR is a dictionary - ir[Variable(i)] returns statement i - this creates a direct link to the statement called.
These will be used to generate the reverse code (equation $\ref{eq:reverse}$) in the next section.
Next, iterate over each statement in the IR.
For each statement if it is an expression :call and not part of a special ignored list, replace it with three calls: the first is to pullback and then two calls to getindex to get the output variable v and back function J from the tuple t:
for (v, st) in pr
ex = st.expr
if isexpr(ex, :call) && !ignored(ex)
t = insert!(pr, v, stmt(xcall(Main, :pullback, ex.args...), line = st.line))
pr[v] = xcall(Base, :getindex, t, 1)
J = push!(pr, xcall(:getindex, t, 2))
push!(calls, v)
push!(pullbacks, J)
end
endAfter working through all the statements, a final statement is added which returns a tuple with the output of the function and a Pullback struct which stores all the pullbacks.
In the last step the pipe is converted back into an IR.
pb = Expr(:call, Pullback{T}, xcall(:tuple, pullbacks...))
return!(pr, xcall(:tuple, returnvalue(block(ir, 1)), pb))
finish(pr), calls
endThis code requires a definition for the Pullback struct as well as the ignored function.
There are no closures in lowered Julia code, so instead Zygote.jl stores the pullbacks in a generic struct:
struct Pullback{S,T}
data::T
end
Pullback{S}(data) where S = Pullback{S,typeof(data)}(data)In the next section this struct will be turned into a callable struct.
That is, for back=Pullback{S}(data), we will create a generated function that dispatches on itself: (j::Pullback)(Δ) so that we can call back(Δ). This back has all the information to generate the reverse pass independently of the forward pass: the method can be retrieved using meta(S) and the relevant data and input parameters from back.data.
Here is the ignored functions list (source):
function ignored(ex::Expr)
f = ex.args[1]
ignored_f(f)
end
ignored_f(f) = f in (
GlobalRef(Base, :not_int),
GlobalRef(Core.Intrinsics, :not_int),
GlobalRef(Core, :(===)),
GlobalRef(Core, :apply_type),
GlobalRef(Core, :typeof),
GlobalRef(Core, :throw),
GlobalRef(Base, :kwerr),
GlobalRef(Core, :kwfunc),
GlobalRef(Core, :isdefined)
)Running this code:
world = Base.get_world_counter()
T = Tuple{typeof(f), Float64, Float64}
pr, calls =_generate_pullback_via_decomposition(T, world)gives the IR at the start.
3.5 Convert
To evaluate the IR it needs to be converted into a CodeInfo struct.
Zygote.jl uses IRTools.Inner.update! to modify the existing struct in meta_T.code.
To me, it makes more sense to construct a new code info block directly from the IR using a slightly modified version of IRTools.Inner.build_codeinfo:
using IRTools: arguments
using IRTools.Inner: dummy_m, update!
function build_codeinfo_(ir::IR)
ir = copy(ir)
ci = Base.uncompressed_ir(dummy_m)
ci.inlineable = true
for arg in arguments(ir)
@static if VERSION >= v"1.10.0-DEV.870"
isnothing(ci.slottypes) && (ci.slottypes = Any[])
push!(ci.slottypes, Type)
end
push!(ci.slotnames, Symbol(""))
push!(ci.slotflags, 0)
end
#argument!(ir, at = 1) # argument for #self# might already exist
update!(ci, ir)
endThis can now be used in _generate_pullback:
using IRTools: argument!, varargs!, pis!, slots!
function _generate_pullback(world, f, args...)
T = Tuple{f, args...}
if (has_chain_rrule(T, world))
return :(rrule(f, args...))
end
g = _generate_pullback_via_decomposition(T, world)
if isnothing(g)
return :(error("No method found for ", repr($T), " in world ", $world))
end
m, pr, backs = g
pr = varargs!(m, pr, 1) # add getfield for each index in args, offset by 1 for f
pr = slots!(pis!(pr))
argument!(pr, at = 1) # add #self#
ci = build_codeinfo_(pr)
ci.slotnames = [Symbol("#self#"), :f, :args]
ci
endTesting (you should redefine the @generated pullback function first):
world = Base.get_world_counter()
pr = _generate_pullback(world, typeof(f), Float64, Float64) # CodeInfo(...)
z, back = pullback(f, 1.0, 2.0) # (0.2,Pullback{...})3.6 Reverse
The goal is to now turn Pullback into a callable struct so that we can call back(1.0) to evaluate equations $\ref{eq:reverse}$ and $\ref{eq:accumulate}$.
With typeof(back) and back.data we have all the information to do this independent from the forward pass.
The result will be:
(%1, %2)
%3 = Base.getfield(%1, :data)
%4 = Base.getindex(%3, 1)
%5 = Base.getindex(%3, 2)
%6 = Base.getindex(%3, 3)
%7 = (%6)(%2)
%8 = Base.getindex(%7, 1)
%9 = Base.getindex(%7, 2)
%10 = Base.getindex(%7, 3)
%11 = (%5)(%10)
%12 = Base.getindex(%11, 1)
%13 = Base.getindex(%11, 2)
%14 = Base.getindex(%11, 3)
%15 = (%4)(%14)
%16 = Base.getindex(%15, 1)
%17 = Base.getindex(%15, 2)
%18 = Base.getindex(%15, 3)
%19 = Main.accum(%9, %13)
%20 = Main.accum(%17, %18)
%21 = Base.tuple(nothing, %19, %20)
return %21Although harder to read, this code represents the same code as the expressions in part 2.
As with the forward pass, an internal function _generate_callable_pullback will do most of the work:
using IRTools: blocks, meta, slots!, inlineable!
function _generate_callable_pullback(j::Type{<:Pullback{S, T}}, world, Δ) where {S, T}
m = meta(S; world=world)
ir = IR(m)
isnothing(ir) && return :(error("Non-differentiable function ", repr(args[1])))
length(blocks(ir)) == 1 || error("control flow is not supported")
back = reverse_differentiate(ir)
back = slots!(inlineable!(back))
ci = build_codeinfo_(back)
ci.slotnames = [Symbol("#self#"), :Δ]
ci
endThe reverse_differentiate function is a simplified version of Zygote.adjoint and Zygote.reverse_stacks!.
To start, a dictionary is created to store the gradients.
It maps variable names (symbols) to an array of gradients.
It is not accessed directly (e.g. grads[x]) but rather through the closure functions grad and grad! which automatically handle the arrays.
The first gradient stored is %2=Δ associated with the final return value of the forward pass.
(xaccum will be defined shortly.)
using IRTools: argument!, arguments, isexpr, returnvalue, xcall, return!
function reverse_differentiate(forw::IR)
grads = Dict()
grad!(x, x̄) = push!(get!(grads, x, []), x̄)
grad(x) = xaccum(get(grads, x, [])...)
ir = empty(forw)
self = argument!(ir, at = 1, insert=false)
grad!(returnvalue(block(forw, 1)), IRTools.argument!(ir))The first statement retrieves the data field in the struct.
data = push!(ir, xcall(:getfield, self, QuoteNode(:data)))Next the code retrieves all the calls with pullbacks from the primal and loops over them, calling the pullbacks one by one.
For each call it also loops over the input arguments and unpacks them one by one.
Each variable’s gradient is added to grads and may be used later in the loop.
pr, calls = primal(forw)
pullbacks = Dict(calls[i] => push!(ir, xcall(:getindex, data, i)) for i = 1:length(calls))
for v in reverse(keys(forw))
ex = forw[v].expr
if isexpr(ex, :call) && !ignored(ex)
Δs = push!(ir, Expr(:call, pullbacks[v], grad(v)))
for (i, x) in enumerate(ex.args)
grad!(x, push!(ir, xcall(:getindex, Δs, i)))
end
end
endFinally, the last call retrieves all the necessary gradients for the input arguments and returns the IR:
return!(ir, xcall(:tuple, [grad(x) for x in arguments(forw)]...))
endThis code calls a xaccum function. It is as follows:
xaccum() = nothing
xaccum(x) = x
xaccum(xs...) = xcall(Main, :accum, xs...)The xaccum function calls an internal accumulate function if it acts on multiple inputs.
At its simplest, accum is the same as sum.
However it also handles nothing inputs, Tupless and NameTuples (source).
accum(x, y) = x === nothing ? y : y === nothing ? x : x + y
accum(x::Tuple, ys::Tuple...) = map(accum, x, ys...)
accum(x, y, zs...) = accum(accum(x, y), zs...)
@generated function accum(x::NamedTuple, y::NamedTuple)
# assumes that y has no keys apart from those also in x
fieldnames(y) ⊆ fieldnames(x) || throw(ArgumentError("$y keys must be a subset of $x keys"))
grad(field) = field in fieldnames(y) ? :(y.$field) : :nothing
Expr(:tuple, [:($f=accum(x.$f, $(grad(f)))) for f in fieldnames(x)]...)
endExamples:
accum(1, 2, nothing, 3) # 6
accum((1, 2), (3, 4)) # (3, 6)
accum((;a=3, b=2), (;a=1)) # (a = 4, b = 2)Finally, dispatch on the Pullback struct to turn it into a callable struct:
@generated function (methodinstance::Pullback)(Δ)
_generate_callable_pullback(methodinstance, nothing, Δ)
endfunction _callable_pullback_generator(world::UInt, source, self, Δ)
ret = _generate_callable_pullback(self, world, Δ)
ret isa Core.CodeInfo && return ret
stub = Core.GeneratedFunctionStub(identity, Core.svec(:methodinstance, :Δ), Core.svec()) # names must match symbols in _generate_callable_pullback
stub(world, source, ret)
end
@eval function (j::Pullback)(Δ)
$(Expr(:meta, :generated, _callable_pullback_generator))
$(Expr(:meta, :generated_only))
endTesting:
f(a,b)=a/(a+b*b)
z, back = pullback(f, 2.0, 3.0) # (0.1818, Pullback{...})
_generate_callable_pullback(typeof(back), nothing, Float64) # CodeInfo for IR at start
back(1.0) # (nothing, 0.0744, -0.0991)The results should match equation $\ref{eq:rollup}$:
a, b = 2.0, 3.0
ā = abs2(b)/abs2(a+abs2(b)) # 0.0744
b̄ = -2*a*b/abs2(a+abs2(b)) # -0.09914 Conclusion
This code works well enough for this simple case. It also works for the trigonometry example from part 1:
f(x) = sin(cos(x))
z, back = pullback(f, 0.9) # (0.5823, Pullback{...})
back(1.0) # (nothing, -0.6368) However it will fail for the polynomial model:
struct Polynomial{V<:AbstractVector}
weights::V
end
(m::Polynomial)(x) = evalpoly(x, m.weights)
(m::Polynomial)(x::AbstractVector) = map(m, x)
model = Polynomial([3.0, 2.0, -3.0, 1.0])
x = [1.0, 2.0, 3.0, 4.0]
pullback(model, x) # ERROR: No method found for Tuple{typeof(fieldtype) ....}The error is raised five levels down:
pr1 = _generate_pullback(world, Polynomial, Vector{Float64})
pr2 = _generate_pullback(world, typeof(map), Polynomial, Vector{Float64})
pr3 = _generate_pullback(world, typeof(Base.Generator), Polynomial, Vector{Float64})
TT = Type{Base.Generator{Vector{Float64}, Polynomial{Vector{Float64}}}} # %9
pr4 = _generate_pullback(world, TT, Polynomial, Vector{Float64})
pr5 = _generate_pullback(world, typeof(Core.fieldtype), TT, 1) # errorThis can be fixed by explicitly defining a pullback for map.
These and other extensions will be the goal of part 4.
-
Presumably the reason the Julia team tried to prevent reflection in generated functions is that it interferes with the compilers ability to properly predict, trigger and/or optimise compilations. ↩
-
Zygote.jl has more complex rules which also consider other fallbacks, key word arguments and a possible opt out through a
no_rrule. ↩