Technical details of the blockchain file system.
This series is split into two parts. Part 1 describes the high level details of the program I made and what it can do. Part 2 goes into the technical details of the C# program.
Please see my GitHub repository for the full code. This post only gives an overview of the classes.
Design
The Entity Relationship Diagram for the program is very basic:
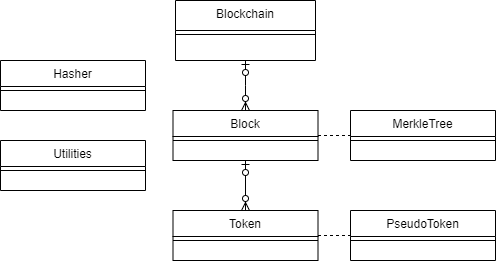
As one would expect, there is a single blockchain which can own multiple blocks, and those blocks can own multiple tokens. There are a few extra helper classes: Hasher, Utilities, MerkleTree and PseudoToken. The actual program uses more classes, including several frontend classes and a few classes for loading from JSON. I’m not going to describe those here.
I wrote the code from the bottom up: first PseudoTokens, then Tokens, then Blocks and finally Blockchains. However I am going to describe it from the top down, as I think that is better for understanding.
Classes
Utilities and Hasher
The Utilities class has two functions for converting to and from Unix dates to C# dates.
It has a Bytes_add_1 function which is used in the proof of work algorithm to increment an array of bytes.
The Hasher class abstracts the SHA-256 algorithm and handles the conversion between bytes, hexadecimal numbers and strings. It itself uses the inbuilt C# System.Security.Cryptography class to abstract the hashing.
A string such as “1a” can either be interpreted as a string or as a hexadecimal number.
If it is interpreted as a string, its byte representation is found with ASCII values: {49, 97}.
If it is interpreted as a hexadecimal number, it needs to be converted to a decimal number first: $1a=1(16) + 10 = 26$.
Hence the byte representation is {26}.
It is important to not mix these two situations because they result in different hashes.
Blockchain
This is a stub of the Blockchain class:
public class Blockchain
{
// attributes
public string Name { get; set ; }
[JsonIgnore]
public string BlockchainDirectory { get; set ; }
public const int Version = 1;
[JsonConverter(typeof(UnixDateTimeConverter))]
public DateTime TimeStamp { get; private set ; }
[JsonIgnore]
public bool Verified {get; private set;}
[JsonIgnore]
public const int MAX_DIFFICULTY = 256;
public List<Block> Blocks {get; private set;}
// constructors
public Blockchain(string directory_="") {/* code */}
public Blockchain(string directory_, DateTime timeStamp_){/* code */} // for loading
// properties
public Block Front() {return this.Blocks[0];}
public Block Back() {return this.Blocks[this.Blocks.Count - 1];}
public Block At(int index) {return this.Blocks[index];}
public int Height() {return this.Blocks.Count;}
public int Index() {return this.Blocks.Count - 1;}
// functions
public Block MakeBlock(){/* code */}
public void CommitBlock(){/* code */}
public bool Verify(){/* code */}
public void Print(bool printBlocks=true){/* code */}
public static bool IsValidProof(byte[] bytes, int target){/* code */}
public static bool IsValidProof(string hash, int target){/* code */}
uint ProofOfWork(byte[] bytes, uint target, uint start = 0){/* code */}
} //class BlockchainThe only fully public attributes are Name and BlockchainDirectory. They are not included in any hashes or data checks.
The rest are set privately.
MakeBlock() is a helper function to ensure that blocks increment their indices properly and carry over previous hashes.
Otherwise blocks can be created independently of the blockchain with their own constructors.
CommitBlock() does multiple checks before committing a block:
- Indices must be sequential.
- The previous block hash must match the value stored in the new block.
- The previous block creation time must be before the new block’s creation time.
- The new block’s creation time must be before the system time - it cannot be in the future.
- The blockchain must be verified
After these checks it will call the ProofOfWork() function.
Finally it will append the block to the list of blocks.
Verify() works by calling each block’s Verify() function.
Block
This is a stub of the Block class:
public class Block
{
// attributes
[JsonIgnore]
public string BlockDirectory { get; set ; }
public const int Version = 1;
public int Index { get; private set; }
public uint Target { get; set; }
public uint Nonce { get; set; }
public string PreviousHash { get; private set; }
public string MerkleRoot {get; private set ; }
[JsonConverter(typeof(UnixDateTimeConverter))]
public DateTime TimeStamp { get; private set ; }
public Dictionary<string, Token> Tokens { get; private set; }
[JsonIgnore]
public bool Verified {get; private set;}
// constructors
public Block(int index_, string previousHash_, string directory_=""){/* code */}
//for loading:
public Block(int index_, string previousHash_, string directory_, DateTime timeStamp_, uint target, uint nonce){/* code */}
// functions
public string StageToken(PseudoToken pseudotoken){/* code */}
public void Print(){/* code */}
public bool Verify(){/* code */}
public string CalcMerkleRoot(){/* code */}
public byte[] getHeader(){/* code */}
public string Hash(){/* code */}
} //class BlockAgain the attribute for the directory is public. Proof of work is not essential in this program, so Target and Nonce are both public variables. Otherwise, all other attributes are set privately.
StageToken() adds a token to the Dictionary Tokens.
It converts a PseudoToken, which is a struct with information about the Token, to a fully fledged Token which is linked to a valid file path.
The Block hash is calculated by hashing the Block header. This is an 80 byte array which is created by concatenating the following attributes together:
| bytes | |
|---|---|
| version | 4 |
| previousHash | 32 |
| MerkleRoot | 32 |
| TimeStamp | 4 |
| Target | 4 |
| Nonce | 4 |
The MerkleRoot is a single hash which represents all of the Token hashes. Here is a graphical representation of the Merkle Tree:
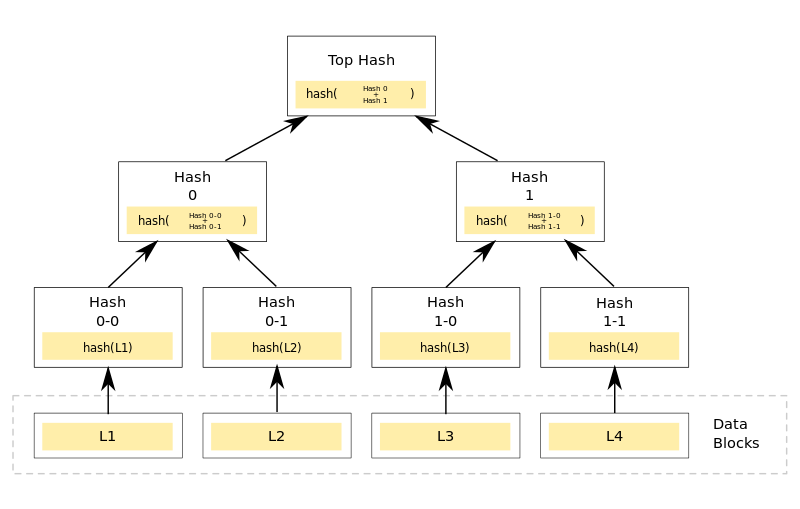
Each of the Token hashes from L1 to Ln are paired together and hashed, then each of the resultant hashes are paired and hashed, and so on until only one hash remains. The class MerkleTree implements this hashing tree. It does not store the actual tree; it just returns the final hash.
Verify() does checks for the Block as well as calling each Token’s Verify() function.
Token
This is a stub of the Token class:
public class Token
{
//Attributes
[JsonConverter(typeof(UnixDateTimeConverter))]
public DateTime TimeStamp { get; private set; }
public string Author { get; private set; }
public string UserName { get; private set; }
public string FileName { get; private set; }
public string FileHash { get; private set; }
// constructors
public Token(PseudoToken t){/* code */}
// for loading:
public Token(string userName_, string fileName_, string author_, DateTime timeStamp, string fileHash_){/* code */}
// functions
public static string GetFileHash(string filePath){/* code */}
public void Print(string dir =""){/* code */}
public byte[] Serialise(){/* code */}
public string Hash(){/* code */}
public bool Verify(string dir =""){/* code */}
} //class TokenThe token is linked to a file, but I’ve chosen not to store the file data in it.
It only stores the file name. The file data is loaded each time it is needed.
This requires knowing the directory where the file resides
but I’ve chosen not to store it.
It therefore needs to be passed to the Print() and Verify() functions.
If a file is not found during printing, a warning is printed. But if a file is not found during verification, an error is thrown.
The Author and UserName attributes are manual inputs. The TimeStamp is the creation time of the token. I’ve thought about extracting the metadata from the file as well e.g. file creation date and file author. However I don’t think it will add much value.
Serialise() is the equivalent of a block’s GetHeader(). It creates a byte array which is then hashed.
This byte array has a variable length and is formed as follows:
| bytes | |
|---|---|
| UserName | variable |
| FileName | variable |
| Author | variable |
| FileHash | 32 |
| TimeStamp | 4 |
The plain text information is converted to bytes according to ASCII codes, and the FileHash is converted from hexadecimal. As I mentioned before, it’s important to not mix these two conversions.
PseudoToken
A PseudoToken is a struct which holds all the data for creating a Token. This is the whole struct:
public struct PseudoToken
{
public string UserName;
public string FilePath;
public string Author;
public PseudoToken(string userName, string filePath, string author)
{
this.UserName = userName;
this.FilePath = filePath;
this.Author = author;
}
} Conclusion
Those are all the main classes in my file. I am also proud of my command line interface, but that is enough for its own post.
I hope you’ve enjoyed learning about the blockchain, and are even ready to make your own.